
In the ever-evolving world of artificial intelligence, the ability of large language models (LLMs) to understand and generate human-like text has been nothing short of revolutionary. However, an intriguing development is taking these capabilities even further: Retrieval-Augmented Generation (RAG) and Fine-Tuning LLMs. This blog, rooted in my research within Evanke Labs, explores these advanced techniques, presenting their functions, advantages, limitations, and practical applications, all while leveraging insights from our proprietary TACIT solution.
Understanding the Basics
What are Large Language Models (LLMs)?

LLMs like GPT-3 and BERT have transformed how we interact with machines. These models are trained on vast amounts of text and learn to predict and generate responses that can be eerily similar to something a human might write. They are utilized in various applications, from writing assistance to chatbots and more.

Large Language Models (LLMs) like GPT-3 and GPT-4 are powerful tools capable of generating human-like text based on the patterns they’ve learned from vast amounts of data. However, one of the fundamental limitations of these models is their inability to access real-time external data or specific organizational knowledge. Since these models are typically pretrained on static datasets, they remain unaware of any information that was not part of their training. This lack of awareness can result in outputs that are outdated, irrelevant, or missing critical contextual details specific to a particular domain or recent developments.
To mitigate this, users might attempt to incorporate relevant data into the input provided to the LLM. However, this approach quickly runs into a significant hurdle: token limits. LLMs have a maximum token limit that restricts the amount of text they can process at once. For example, if a model has a token limit of 4,000 to 8,000 tokens, any input exceeding this limit must be truncated or summarized. This truncation can lead to a loss of important context, reducing the effectiveness of the generated response. For organizations dealing with extensive documentation, detailed case histories, or large datasets, these token limits pose a serious challenge.
Moreover, when attempting to integrate sensitive organizational data into these models, security and privacy concerns arise. Pretrained LLMs are general-purpose and not tailored to the specific security requirements of individual organizations. Feeding proprietary or confidential information into these models without careful consideration could expose sensitive data, creating potential vulnerabilities.
Concept of RAG

Retrieval-Augmented Generation (RAG) is an approach that enhances LLMs by integrating information retrieved from external sources or an organization’s data, into the text generation process of the LLMs. RAG operates in two stages:
- Retrieval: It uses a retrieval model to fetch relevant information from a massive external database when prompted with a user query.
- Augmented Generation: In this step, the LLM is further prompted with the information retrieved from the previous step to augment and generate the final response, that is not only relevant but also grounded in factual accuracy and context.
LLM Fine-Tuning
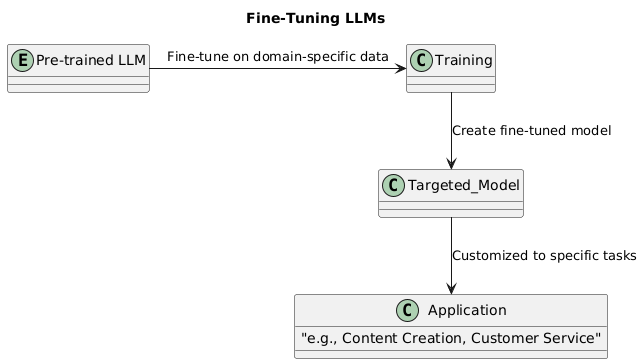
Fine-tuning, on the other hand, is a technique that refines a pre-trained LLM to perform better on tasks within a specific domain of knowledge, using a targeted dataset. This process allows the LLM to adapt to the nuances of a particular domain, field, style etc., thereby enhancing its efficacy and specificity. An example can be seen in TACIT’s application to legal texts, where the model is fine-tuned to understand and predict outputs based on historical data from FOIA cases.
RAG: Expanding Knowledge Beyond Built-in Learning of LLMs
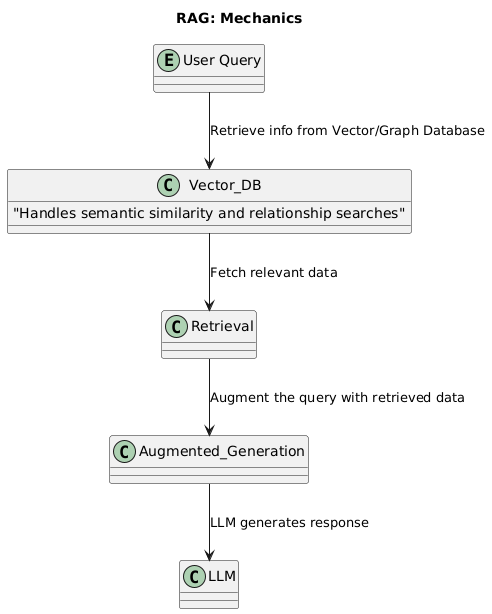
RAG’s ability to pull information from external sources allows LLMs to provide answers that are up-to-date and contextually rich. Here’s a deeper look into how RAG works:
The Mechanics of RAG
Leveraging Vector Databases and Graph Databases: At the underlying level, RAG uses vector or graph databases to retrieve information. While vector databases are great for semantic similarity in searches (e.g., product feature related searches are matched with corresponding sections within a product manual), graph databases excel in precise retrieval of information pertaining to relationships between entities (e.g., criminal actors and their relationship to other actors, crimes and other criminal networks). Once the relevant data is fetched, from the vector or graph database based on the need for semantic search or relationship search, it is augmented with the user query to give the model a context-expanded prompt, enhancing the generation’s relevance and depth.
Pros of RAG
- Enhances accuracy with real-time data fetching with enhanced context.
- Increases contextual depth of response from across multiple data sources.
- Supports explainability by tracing the external or organization’s information source.
Cons of RAG
- Dependency on external databases introduces complexity and attack surface for potential hacks.
Fine-Tuning LLMs: Customizing AI to Niche Domains
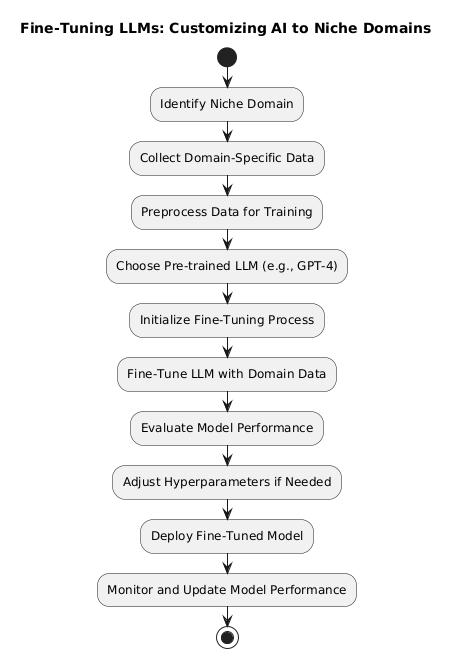
Fine-tuning personalizes the LLM’s functioning to offer improved performance on specifically tailored tasks or within particular sectors.
The Fine-Tuning Process
- Training: As we know, LLMs are trained on publicly available data but not on any organization specific domain data, LLM needs additional training on this dataset, allowing it to grasp subtleties and specifics of the target domain – which is why it is called a finetuned model.
- Selection of Data: Crucial to the above fine-tuning’s success is the choice of relevant, high-quality data (e.g., specific organizational domain data such as HR, contracts, etc.).
Pros of LLM finetuning
- Boosts domain-specific understanding.
- Offers more control over text generation, critical in tasks like content creation.
Cons of LLM finetuning
- Risk of corrupting the foundational knowledge of the LLM by overfitting on the fine-tune dataset.
- Potentially limited applicability outside the trained domain.
- If the underlying data is updated or expanded, the entire model may need to be retrained to incorporate the new information. This retraining process can be resource-intensive and time-consuming, especially for large models, making it less practical in dynamic environments where data frequently changes.
Practical Applications and Case Studies
- Chatbots and Customer Service: Using RAG, chatbots can provide answers not just based on an existing knowledge base of customers, products, services etc. but from a continuously evolving knowledge base. Fine-tuning these models on customer service dialogue can make them more sensitive to user needs.
- Content Generation: LLMs, fine-tuned on specific genres or styles, can produce creative and engaging material, from marketing campaigns to fiction writing.
- Educational Tools: RAG can enable educational bots to pull in the most current information, while fine-tuning ensures responses are pedagogically appropriate.
RAG vs Fine-Tuning: Which One to Choose?
The decision between RAG and fine-tuning largely depends on the specific requirements of your application:
- Use RAG if your application benefits from real-time dynamic data and requires high accuracy and factual grounding.
- Opt for Fine-Tuning if your focus is on depth in a particular field or customization of language style.
Future Outlook and Advancements
In real-world applications, RAG and fine-tuning manifest uniquely. Tools like TACIT demonstrate the success in using fine-tuned models for specific organizational needs. For instance, TACIT uses fine-tuning and machine learning pipelines to predict legal decisions efficiently, providing an edge in managing and automating the appeals and hearing processes.
The integration of both techniques, creating hybrid models that leverage both real-time data retrieval (RAG) and nuanced domain understanding (fine-tuning), represents a significant step forward. As AI continues to advance, these models are likely to become more sophisticated, with better understanding, more natural interactions, and an enhanced ability to learn from their environments.




