
Introduction
In my journey of building and refining Retrieval-Augmented Generation (RAG) pipelines, I’ve encountered multiple approaches—Naive RAG, Self-RAG, and Graph RAG—each addressing distinct challenges in AI-powered question answering. While working on projects such as CONVAID (my text-to-SQL project) and document Q&A systems using Palantir Foundry, I experimented with these variations to optimize retrieval accuracy, reduce hallucinations, and enhance reasoning for complex queries.
RAG systems bridge the gap between large language models (LLMs) and domain-specific knowledge by fetching relevant external data during generation. Through practical implementation and rigorous testing, I gained a deeper understanding of how each approach—Naive RAG, Self-RAG, and Graph RAG—performs in real-world scenarios. Here’s a breakdown of my findings.
1. Why Choose Retrieval-Augmented Generation (RAG)?
When I started integrating RAG models into my projects, I quickly realized the limitations of vanilla LLMs:
- Outdated or Generic Information – LLMs often lacked domain-specific knowledge.
- Hallucination Risks – Without grounding, models would fabricate facts, creating inconsistencies.
- Context Limitations – Static models struggled with dynamically evolving datasets.
RAG mitigates these issues by combining retrieval and generation—retrieving external knowledge and injecting it into the model’s context. In my experiments, I applied RAG for financial Q&A over earnings call transcripts, document-based search tasks, and SQL query generation pipelines. Here’s how each RAG approach performed.
2. Naive RAG: My Starting Point
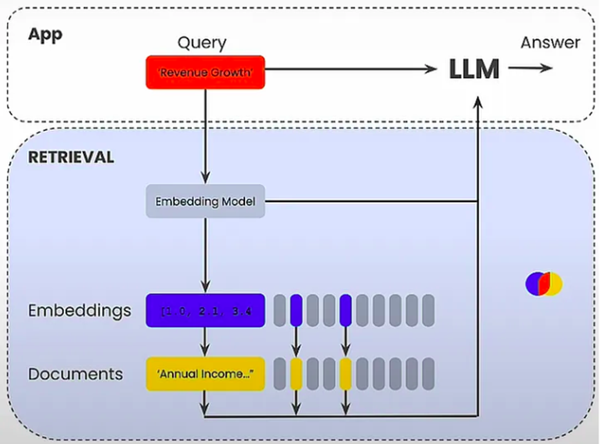
2.1 How Naive RAG Works
In my initial implementations, Naive RAG was a straightforward choice. I used OpenAI’s text-embedding-ada-002 to generate embeddings and stored them in vector databases like ChromaDB and PGVector. The pipeline consisted of:
- Data Collection: Documents (10-Q reports, user manuals) were gathered.
- Chunking: Large documents were split into manageable chunks for improved retrieval.
- Embedding Creation: Document and query embeddings were generated.
- Vector Search: Using cosine similarity, the top-k relevant chunks were retrieved.
- Response Generation: Retrieved chunks were passed to an LLM (e.g., GPT-4) to generate responses.
2.2 Pros I Experienced
- Easy to Implement: Quick to set up and test with minimal configuration.
- Improved Accuracy: Grounding reduced hallucinations and provided context-aware responses.
2.3 Cons I Noticed
- Context Limitation: For complex queries, Naive RAG struggled to synthesize information across multiple chunks.
- Chunk Dependency: The final response was heavily reliant on the coherence of retrieved chunks.
3. Self-RAG: Adding Intelligence Through Reflection
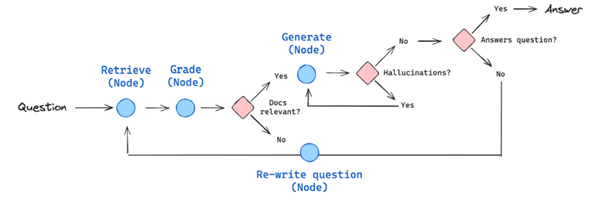
3.1 Why I Moved to Self-RAG
As I worked on improving accuracy for document-based Q&A, I realized Naive RAG’s limitations. To handle more nuanced queries, I implemented Self-RAG, introducing decision-making and self-reflection to dynamically assess whether additional retrieval was necessary.
3.2 How I Structured Self-RAG
- Self-Assessment Nodes: I added reflection points where the model asked itself:
- Should I retrieve more data?
- Is the response aligned with the retrieved knowledge?
- Validation Layer: After generating an initial response, a secondary pass evaluated the output’s relevance and correctness.
3.3 Pros of Self-RAG
- Dynamic Decision-Making: Retrieval happened only when necessary, reducing noise.
- Better Fact-Checking: The self-evaluation stage improved factual correctness.
3.4 Cons I Faced
Increased Complexity: Implementing decision nodes and reflection layers added significant overhead.
4. Graph RAG: Reasoning Beyond Simple Retrieval
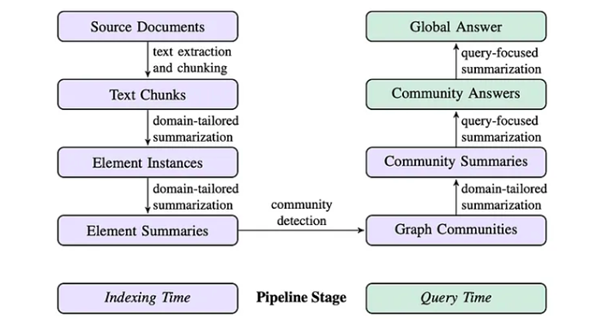
4.1 Why I Turned to Graph RAG
In one of my Palantir Foundry projects, I dealt with highly interconnected data where simple vector retrieval was insufficient. I explored Graph RAG to leverage knowledge graphs and entity relationships for deeper reasoning.
4.2 My Implementation of Graph RAG
- Entity Extraction: Key entities were identified using NLP techniques.
- Graph Construction: I built a knowledge graph where entities and relationships were dynamically linked.
- Community Detection: I partitioned the graph into smaller, context-aware subgroups for efficient querying.
4.3 Pros I Discovered
- Enhanced Reasoning: Graph RAG excelled in multi-hop reasoning and context aggregation.
- Improved Contextual Understanding: Complex queries benefited from the graph’s ability to synthesize diverse knowledge.
4.4 Challenges I Encountered
- Higher Resource Usage: Managing large knowledge graphs was computationally expensive.
- Increased Development Time: Fine-tuning graph traversal and entity extraction added to the complexity.
5. Side-by-Side Comparison: What Worked Best for Me
| Feature | Naive RAG | Self-RAG | Graph RAG |
| Retrieval Strategy | Semantic similarity | Self-assessment | Knowledge graphs |
| Complexity | Low | Medium | High |
| Best Use Cases | Static knowledge bases | High factual accuracy needs | Multi-hop reasoning |
| Scalability | Easy | Medium | Computationally Intensive |
6. Lessons Learned and Key Takeaways
After experimenting with these approaches across different projects, I found that:
- Naive RAG is perfect for quick proof-of-concept deployments where simplicity and speed matter.
- Self-RAG shines in scenarios where factual consistency and output validation are critical, such as legal or financial applications.
- Graph RAG is indispensable when dealing with complex knowledge graphs and requiring multi-step reasoning.
When choosing the right approach for a RAG system, I learned that aligning the retrieval strategy with the complexity of the task yields the best results.
7. Wrapping It Up
My exploration of Naive RAG, Self-RAG, and Graph RAG wasn’t just a theoretical exercise—I implemented, iterated, and refined these approaches to build robust AI systems. From optimizing SQL generation with CONVAID to handling complex document-based Q&A pipelines, each RAG variant offered valuable insights and lessons.
By tailoring the approach to the specific challenges at hand, I was able to improve response accuracy, reduce hallucinations, and enhance the overall performance of my AI workflows. As I continue to push the boundaries of RAG systems, these experiences will undoubtedly shape my future implementations.




