")
Introduction
In the fast-paced world of finance, where decisions hinge on timely and accurate information, I saw an opportunity to enhance how financial documents are queried and analyzed. That’s how FinRAG (Financial Retrieval-Augmented Generation) came to life. I built FinRAG to simplify the querying of financial documents, such as 10-Q reports and earnings call transcripts from major companies like Amazon, Meta, Google, and Microsoft for the quarter ending September 30, 2024. This blog captures my journey, from tackling document ingestion to building a seamless query interface.
Data Uploading: Getting Started with Foundry
The first step was uploading the financial documents to Palantir Foundry. I carefully prepared the documents, ensuring that both 10-Q reports and earnings call transcripts were structured properly for downstream processing. This stage laid the groundwork for all subsequent tasks, ensuring the data was ready for transformation.
Data Processing in Palantir Foundry: Laying the Foundation

Once the documents were uploaded, I designed a data processing pipeline using Palantir’s Pipeline Builder. This involved multiple steps to ensure that the data was processed efficiently:
- Text Extraction: I extracted raw text from the PDF documents to make them machine-readable.
- Chunking: To optimize retrieval efficiency, I split the extracted text into smaller chunks.
- Company Name Annotation: I added company names to the chunks, which significantly improved entity-specific query responses.
- Embedding Creation: Using OpenAI’s ada-002 model, I generated embeddings that converted the text chunks into high-dimensional vectors, making similarity searches faster and more accurate.
- Dataset Creation: Finally, I combined the processed data into a structured dataset, ready for querying and analysis.
Ontology Creation: Structuring for Efficient Querying
To enable fast and accurate query responses, I built an ontology on top of the processed dataset. The ontology included:
- Embedding Column: I configured this column for cosine similarity search to ensure that relevant chunks were retrieved based on semantic similarity to the user’s query.
- Metadata Linking: Key metadata, such as company name and page numbers, was preserved to provide contextual information along with the retrieved content.
This ontology ensured that FinRAG could quickly identify and return the most relevant information.
Building the AIP Pipeline: Powering the Query Engine

Building the AIP (Application Integration Pipeline) was one of the most exciting and challenging parts of the project. I designed this pipeline to handle user queries effectively:
- User Query Input: The pipeline accepts the user’s query through the frontend.
- Similarity Search: I embedded the query and performed a cosine similarity search to match it against the embedded dataset.
- Top Chunk Retrieval: The top 10 most relevant document chunks were retrieved based on similarity scores.
- LLM Integration: The retrieved chunks were passed to an LLM (Large Language Model), which generated a response that was grounded in the retrieved content.
Workshop Building: Crafting an Intuitive Frontend
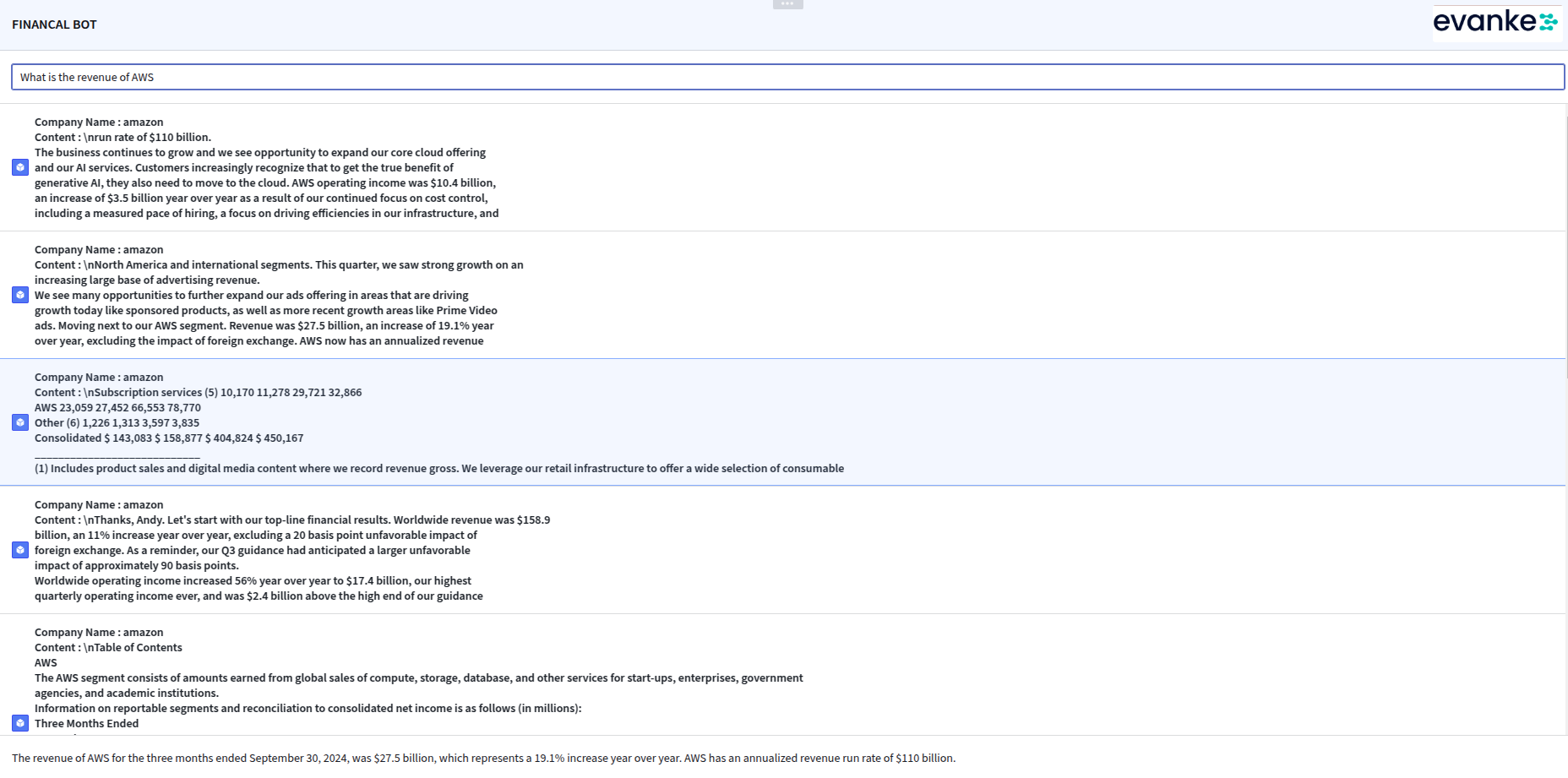
To make the system more accessible and user-friendly, I developed a clean and intuitive frontend interface that connected seamlessly with the backend. The interface allowed users to:
- Submit Queries: Users could enter financial queries effortlessly.
- View Retrieved Chunks: The top 10 relevant document chunks were displayed, enabling users to verify the retrieved content.
- Receive LLM-Generated Answers: The final answer, generated by the LLM, was presented with high factual accuracy by referencing the retrieved content.
End-to-End Workflow: Bringing It All Together
Here’s a quick snapshot of the entire workflow that I meticulously built:
- Document Upload: Financial documents were uploaded to Palantir Foundry.
- Data Pipeline: Documents were processed, chunks were extracted, company names were added, and embeddings were generated.
- Ontology Setup: I created an ontology that enabled cosine similarity-based searches.
- AIP Pipeline: This pipeline handled query processing, chunk retrieval, and response generation.
- Frontend Development: I built a user-friendly interface to ensure seamless interaction for end-users.
Conclusion: Reflecting on the Journey
Building FinRAG was an exciting journey that allowed me to apply my expertise in RAG architectures and Palantir Foundry to solve a real-world problem in the financial domain. By grounding responses in retrieved, relevant content, FinRAG enhances the accuracy and reliability of answers, making it easier for financial analysts and decision-makers to extract insights from complex reports. As the volume of financial data grows, I’m confident that FinRAG will continue to provide a scalable and efficient solution for extracting insights from diverse financial documents.




